

Financial Engineering Concentration and Cornell Financial Engineering Manhattan (CFEM)
Current Headlines
"At CFEM, students learn from practitioners real-world cutting-edge techniques that are applied at some of the leading investment institutions. Through industry-sponsored projects, the students demonstrate to future employers their unique analytical and team-working skills, which allow them to solve problems that firms have struggled with for years.”
--Visiting Professor Marcos Lopez de Prado
Learn more about Cornell Master in Financial Engineering in 2024!
Interested in discovering a unique feature of the CFEM semester? As a Cornell MFE student, you will be working on groundbreaking research alongside industry experts through the Capstone Projects. Watch the 2023 Project Recap Video in which CFEM Head of Research Sasha Stoikov explains this one-of-a-kind opportunity that is not offered anywhere else. Subscribe to our main channel for more content that will convince you to enroll today!
Spring 2024 Event Lineup (all CFEM Events)
2/20 CFEM and UBS AI & Data Research Seminars: Joseph Simonian (Scientific Beta)
3/19 CFEM and UBS AI & Data Research Seminars: Igor Halperin (Fidelity)
4/23 CFEM and UBS AI & Data Research Seminars: Michael Ludkovski (UCSB)
CFEM Testimonials
"CFEM is a community where you can not only gain solid academic experience, but also exchange state-of-the-art insights with outstanding practitioners. You will stand at the cutting edge of the industry." - Hubery Wang, MFE Class of 2019
"The MFE program will equip you with the tools and knowledge you need to succeed. You can tailor your coursework to a specific career path while also building knowledge in fundamental areas." - Sagar Mehta, MFE Class of 2020
Check out our latest brochure highlighting Cornell MFE over the past 10 years (see side menu under "Alumni Testimonials")!
Formally recognized as the Master in Engineering (MEng) with Financial Concentration in the School of Operations Research and Information Engineering (ORIE), Cornell MFE is a career-oriented and application-focused degree that takes you beyond textbook quantitative finance (Cornell MFE info). With its flexible curriculum that encourages the study of data science, optimization, analytics, and computing, in addition to a broad range of courses in finance, the program has a rich history of providing the relevant and practical coursework in line with the demands of the financial industry. Graduates of the program have a U.S. degree in an approved science, technology, engineering, or mathematics (STEM) field (see information on OPT STEM Extension from the Office of Global Learning).
With Cornell MFE, your career is guaranteed to begin in the classroom (Apply to Cornell MFE).
.jpg)
Cornell MFE consists of (3) semesters (Fall-Spring-Fall) and allows for a summer internship after the first year. All students begin their studies on our scenic Ithaca campus, and they will complete their studies at Cornell Financial Engineering Manhattan in the heart of New York City.

For the price of one program, students have a diversity of settings to experience the full range of Cornell University.
Structured to offer a flexible curriculum, Cornell MFE allows students to focus on a career track of their choice. Some of the most popular career tracks include:
- Trading
- Quantitative Portfolio Management
- Financial Data Science/Fintech
- Financial Risk Management
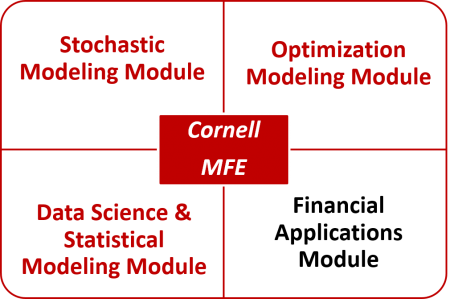
To complete the ORIE Core Requirements, students must take a certain minimum number of credit hours from three modeling and data science modules (see chart above). While the selection of qualifying courses in each module is broad, each course is strategically hand-picked across various departments to offer students the knowledge most sought after in the field of quantitative finance. In addition, students must take certain credit-hours from the Financial Applications module for completion of the financial engineering concentration (MFE). Financial Applications Module includes courses from the Johnson Graduate School of Management and Cornell Financial Engineering Manhattan (CFEM).
CFEM, established in 2007 as a satellite New York City campus for Cornell MFEs, serves to connect our students with alumni and other practitioners working in the field of quantitative finance.
Most of the CFEM coursework is taught by practitioners. Our practitioner lecturers work in the same field as the courses they teach (see full list of faculty). CFEM courses change year to year in response to the fast-paced needs of the financial industry. For specific qualifying courses, please see the ORIE MEng Handbook (pages 6-7 for ORIE Core and pages 11-12 for Financial Applications). Please email us for a copy of the handbook.
The Financial Data Science Certificate (FDSC) is integrated in the curriculum and is designed specifically for students who are interested in deepening their knowledge of machine learning and data science applications. FDSC coursework equips students with the knowledge that brings immediate value to an organization. Upon completion, students will have solid backgrounds in each of the following:
Theory: Understand the value-added and potential uses of data science in finance
Data: Collect/scrape data and create data environment
Application: Apply algorithms and extract insight
Follow us on Facebook CFEM and LinkedIn CFEM